LLM as a Web Server
At June’s Prompt Poets Society meetup, two lines from JD Trask’s talk stuck with me.
Web servers are text in, text out.
And, a bit later:
LLMs are text in, text out.
So what happens if the LLM is the web server? Not a model writing code for a web server, but the model serving every new page itself, fresh HTML invented on the spot.
It’s a terrible idea for all the obvious reasons: every click costs real money, takes seconds instead of milliseconds, and comes back a little different every time. But I was curious, so I built it.
The experiment is called 🔥 token burner 🔥: a web app where the LLM is effectively the view layer.
Instead of talking to a model through a chat box and getting text back, you talk to it through a web page and get another web page back. Buttons, forms, charts, games, controls, and layouts are all just different shapes a conversation can take. Clicking a button isn’t “using the app” in the normal sense. It’s sending the next message.
So it’s not a vibe coding tool, even if it looks like one on the surface. The generated HTML is not the end product. It is the conversation.
Here’s what that looks like in practice. You seed a conversation with a plain-text prompt:
And the reply comes back as a page, not a paragraph:

Not everything on the page costs a new turn. Selecting a planet here expands its details with ordinary client-side JS. But a button like “Deep Dive into Earth” sends the next message in the conversation, and the model renders a fresh page in response. The model draws that line itself while writing each page: what it can handle with the content already on it, and what deserves a whole new turn.
From that one explorer page I drilled into Mars, then Jupiter, then Earth. Three replies, three siblings branching off the same parent turn:
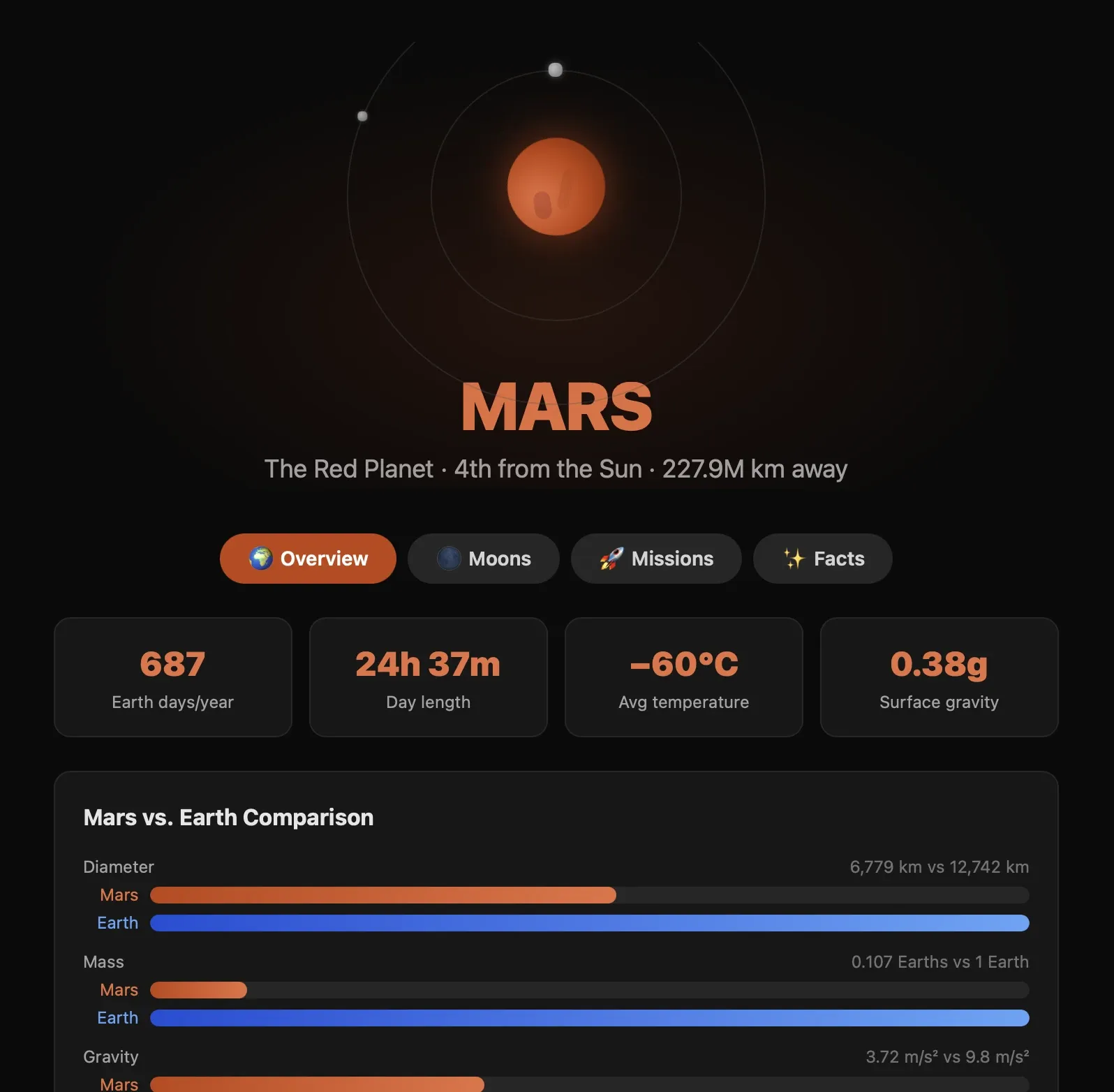
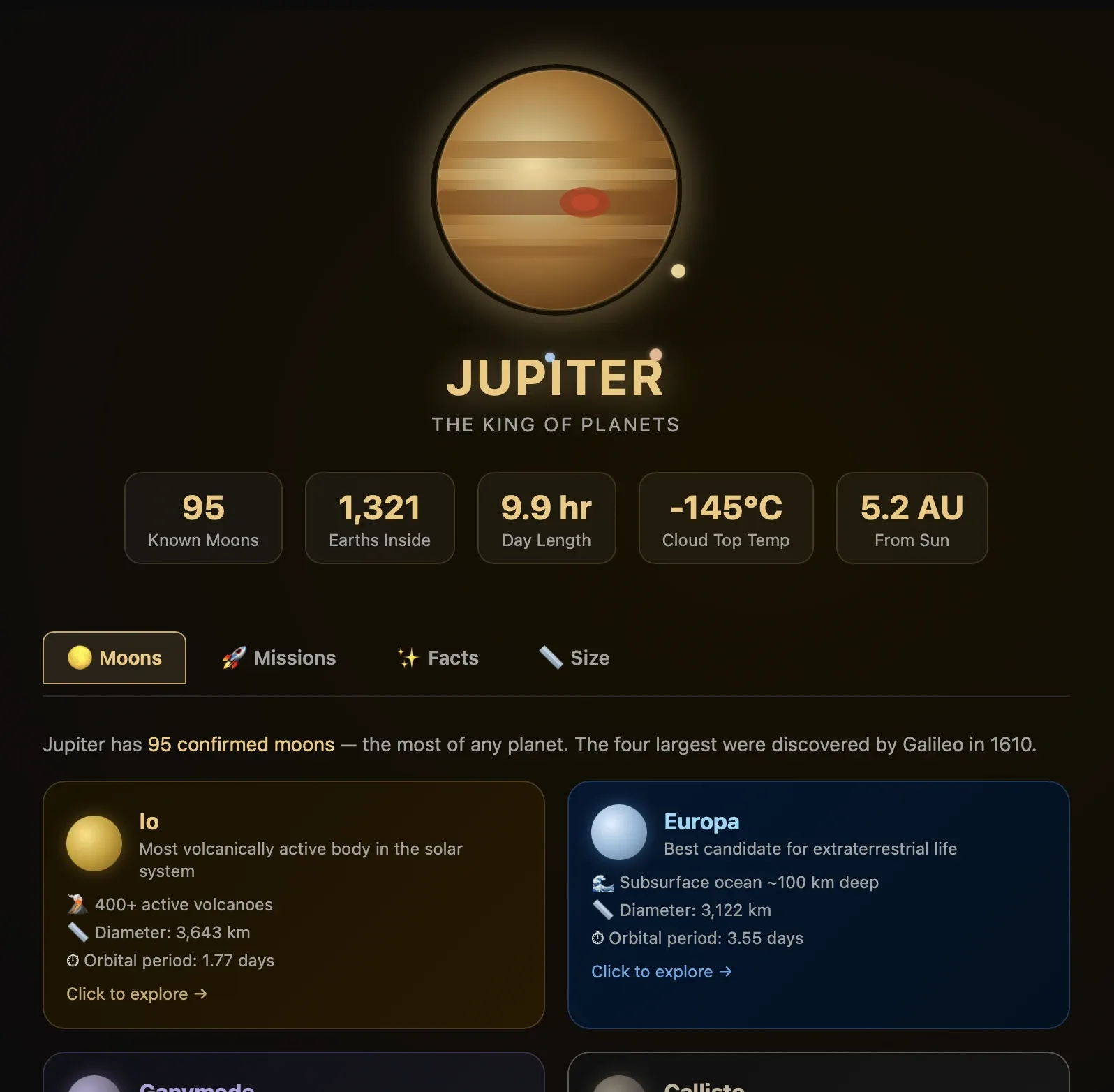
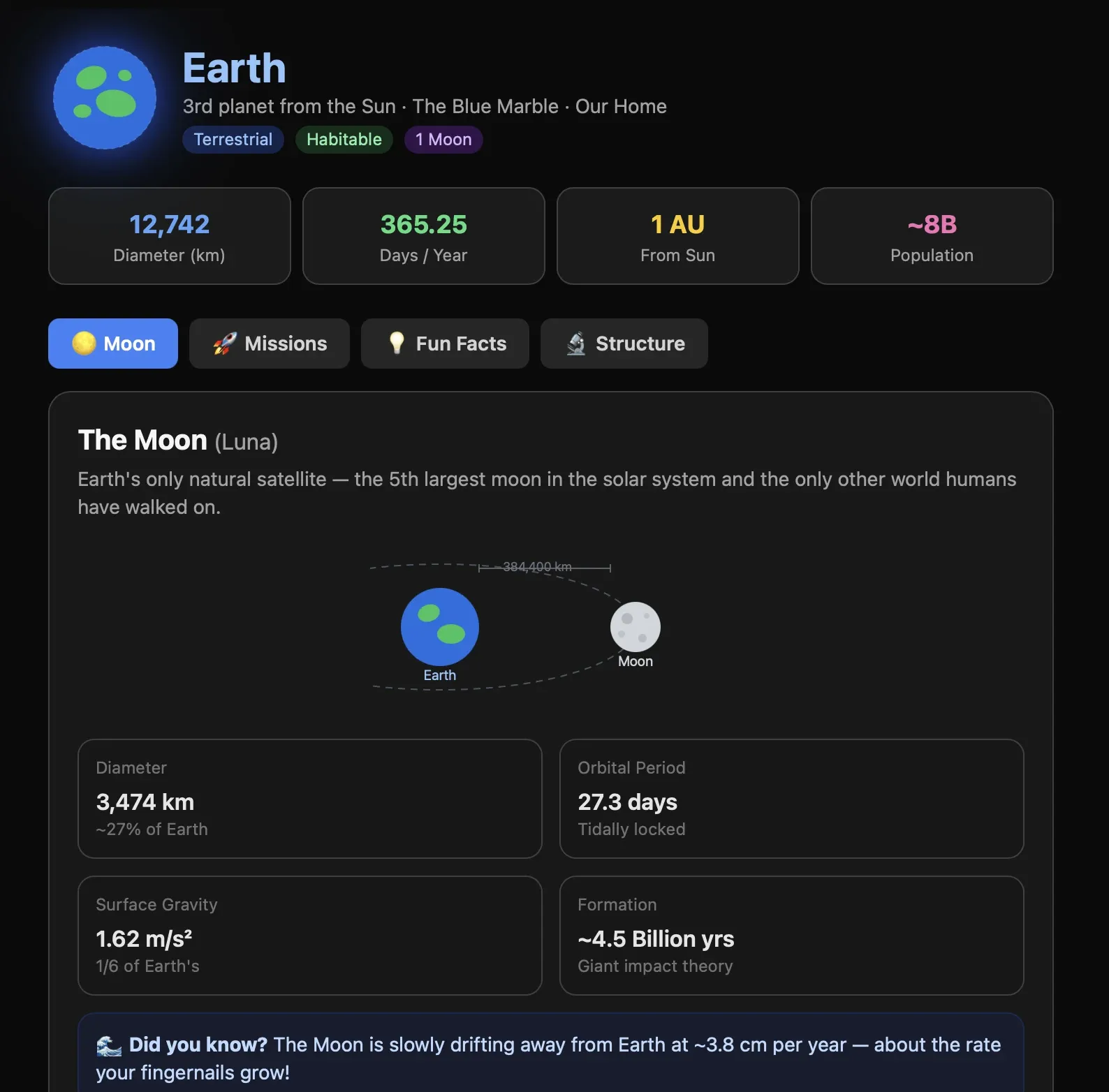
Nobody designed these pages. Each one is a fresh generation, and the model gave each branch its own art direction. Mars went ochre, Jupiter went regal gold, and Earth got the friendly blue treatment. Those links are the live turns, so you can pick up this exact conversation and branch it somewhere I never went.
How a request actually becomes a page
The mechanics are simpler than they sound. Not every interaction round-trips to the model. Plenty of pages have ordinary client-side JS for animations or local UI state, but any element the model wants to make a new turn carries a data-prompt attribute (or a data-prompt-template for forms), and a small injected script turns clicks and submits on those elements into a POST to /c/:convoId/:turnId/act with that prompt as the body. A generated button is literally the next message, waiting to be sent:
<button data-prompt="Drill into Mars"> Explore Mars → </button>
On the server, three things happen:
- Load history. A recursive SQL query walks up the conversation tree via
parent_turn_id, so branched conversations don’t leak sibling turns into context. - Call the model with a forced tool. The new prompt gets appended, and the model is called with
toolChoicelocked to a single tool,render_page({ body_html, summary, style_hints }). It has no choice but to hand back structured HTML. - Render and respond. The
body_htmlgets dropped into a shared template (Tailwind, D3, Chart.js, Three.js, Tone.js all preloaded) and served back as the actual HTTP response forGET /c/:convoId/:turnId.
The one detail that made the whole thing click for me is that the model never sees the raw HTML it generated on previous turns. Only the summary string it writes about itself each turn gets replayed as assistant history. Context stays small. The model is deliberately wasteful with output tokens (hence the name) but frugal about what gets fed back in.
The parts that needed real engineering
Once you’re not just doing a single fun completion, the toy version stops being enough:
- Generation is async. A turn gets inserted as
status: "pending", the LLM call runs in the background, and the page polls a/statusendpoint every second or so, showing a spinner until it’s done. - Branching and dedup. Because turns are a tree keyed by
parent_turn_id, the same prompt fired from the same parent turn reuses the existing generated page instead of burning a fresh generation. - The system prompt has to say what it can’t fake. I explicitly forbid the model from faking “backend functionality” client-side. Anything that needs real logic has to round-trip through another turn instead.
- Navigation is the browser’s job. The model is banned from rendering back buttons. A generated “back” button can’t actually return anywhere; it would just burn a fresh turn imitating an earlier page. The browser’s real back button already works, and walking back up the tree to branch off somewhere new is half the point.
(And yes, since conversation links are shareable, opening someone else’s branch means running whatever JS their prompts talked the model into writing. It’s a toy; treat it like one.)
Is it actually usable? More than it deserves to be. With a frontier model you feel every page generation, and the spinner overstays its welcome. A small fast model like Gemini 3.1 Flash Lite gets surprisingly close to ordinary page-load territory:
And what each of those pages costs:
claude-sonnet-4.6 is the default model, so its averages are built on far
more pages than the others. The rest are smaller, noisier samples.
There’s a model picker on the start page, so you can trade smarter pages for faster, cheaper ones yourself.
Why this was worth building
The interesting part isn’t “look, the LLM can write HTML.” We know it can do that and do it well. The interesting part is watching exactly where the illusion of a real web app breaks down, and what it takes to patch each break.
- State isn’t free. Nothing persists unless it’s explicitly replayed into context. The summary-not-HTML trick is the whole reason this doesn’t collapse under its own token cost by turn ten.
- Consistency requires plumbing, not just a bigger model. Branch dedup, the turn tree, forced tool calls: none of that is the model being smart. It’s scaffolding that keeps the model from contradicting its past turns.
That’s the real payoff of building something like this. Not a novelty web server, but a very fast way to feel out the line between what a model can convincingly improvise and what actually needs a system of record behind it.
What’s next: LLM as a web app
token burner is a closed loop. The model’s only “backend” is its own imagination, so nothing it renders can be wrong in a way that matters. The natural next step is to give it a real backend, wiring the model up to actual tools or MCP servers so the pages it generates reflect real state instead of a plausible guess at it.
The use case I keep coming back to is trip planning. Not booking a specific flight, which is a solved, procedural problem, but the messy part before it: “somewhere warm, good food, not touristy, but my partner hates long flights and we have a toddler.” Nobody fills out a form for that, and it’s exactly the kind of reasoning that resists being turned into a deterministic flow. Real availability via tools keeps the itinerary grounded in what’s actually bookable, but the value isn’t the API calls. It’s a UI that can restructure itself around whatever exception you throw at it next.
Even there, though, not everything should be generated from scratch. token burner already wraps its output in a shared template, so the split I mean isn’t chrome versus content. It’s first-class, reusable components (a booking form, a date picker, an itinerary card) that look and behave the same every time, and that the model can drop into and between the pages it generates. Maybe even whole predesigned pages for the flows that never change. The model keeps improvising the genuinely fluid part: the itinerary, the tradeoffs, the options laid out in response to your latest exception. The dependable parts it composes from a library instead of reinventing them each turn. That mix feels like the more honest version of “LLM as a web app.” Not the model replacing the whole UI layer, but the model handling the one part that’s too fluid to template in advance.
In the meantime, have a play while I still have credit.